Replication of our phone usage based sleep algorithm
28 Sep 2016
What can your phone say about you? A lot, particularly when it comes to sleep.
A recent paper from Cuttone et al. replicated our phone usage based sleep algorithm from the UbiComp 2014 paper. Based on the data from 126 participants, they found that our algorithm performs similarly to their proposed Bayesian model with remarkable accuracy and precision for detecting sleep events (mean accuracy: 0.89 and mean F1-score: 0.83).
While a number of recent studies have used a wide array of sensors on phones (e.g., audio, accelereometer) to assess sleep, our algorithm only uses screen on and off information. The intuition behind our algorithm is that most phone users use their phone right after waking up and before going to sleep. So, the algorithm looks for longest non-usage patterns in the night to identify sleep onset and duration. It also adjusts to individual patterns of phone usage by using a corrective term learned over the initial training period. In our paper, we have provided detailed pseudo-code. You can also see it explained in the slides I presented in UbiComp 2014 (see slide 33 - 37).
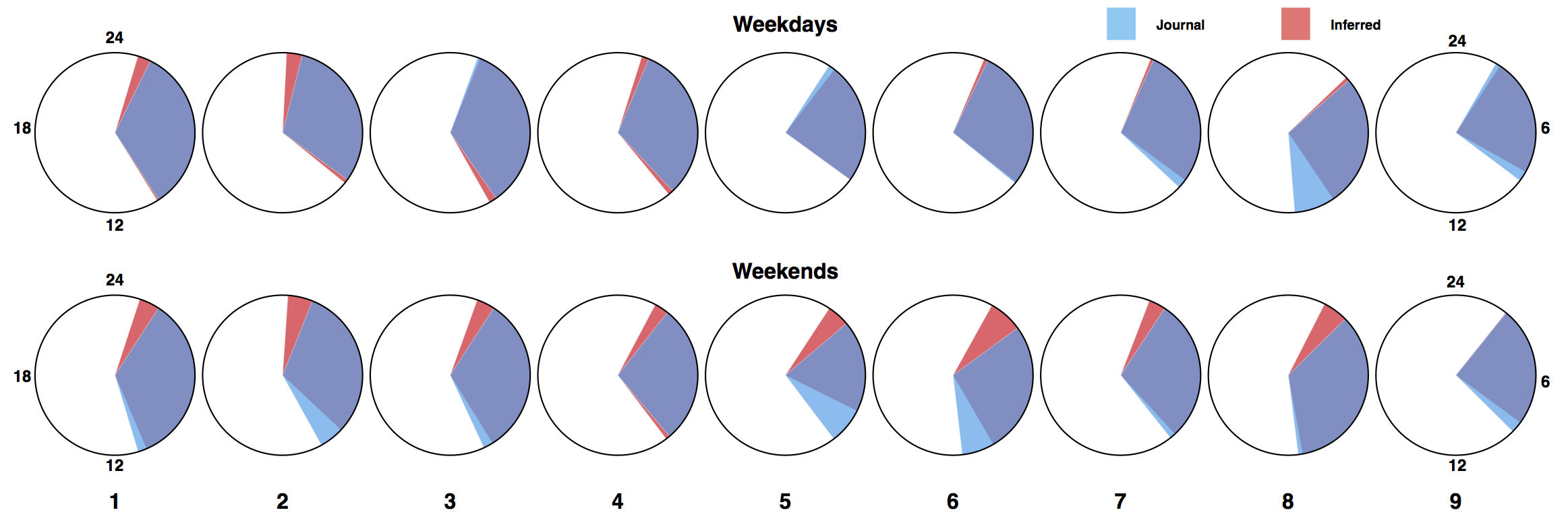 Average sleep onset and duration across participants from phone and journal data. The phone non-usage coincides with sleep events.
Average sleep onset and duration across participants from phone and journal data. The phone non-usage coincides with sleep events.
In our study, we evaluated the algorithm using data from 9 participants over 97 days and found that it can accurately assess sleep onset and duration. However, all our participants were students and from 18–24 age range.
The data used by Cuttone et al., on the other hand, was collected by Sony Mobile from 126 participants over 2–4 weeks. For ground-truth, they use sleep data from wearables instead of journals as we did in our study. So, the high accuracy of our algorithm in this new and potentially more diverse dataset indicates that it is quite robust.
I am really glad that they decided to replicate our algorithm on this new dataset. Given that the algorithm achieves high accuracy but is very low cost (both data and computation wise), I hope these findings will encourage others to adopt it for passive and automated sleep assessment in populations mostly comprised of phone users.
On a broader note, I think, these results also serve as a reminder about the usefulness of soft-sensing — data about how we use our digital devices. Given much of our daily behavior now gets mediated through these devices, it is of no surprise that soft-sensing can provide unique insights about our behavior and contexts.